Кластер Proxmox з двох вузлів
У цьому пості ми розглянемо, як зробити кластер Proxmox з двох вузлів і як це все буде працювати.
Введення
Proxmox Cluster – це гніздо віртуалізації, що складається з декількох вузлів Proxmox VE, об’єднаних в єдину систему управління. Кластер Proxmox дозволяє адміністраторам керувати кількома фізичними серверами як єдиним цілим, забезпечуючи високу доступність і відмовостійкість віртуалізованої інфраструктури.
До переваг кластера Proxmox можна віднести:
- Висока доступність: у разі виходу вузла з ладу віртуальні машини автоматично мігрують на інші справні вузли, забезпечуючи безперервність системи.
- Балансування навантаження: ресурси кластера можуть бути рівномірно розподілені між вузлами для оптимальної продуктивності та ефективного використання ресурсів.
- Централізоване управління: адміністратори можуть керувати всіма вузлами кластера через єдиний інтерфейс керування Proxmox VE.
- Масштабованість: При необхідності ви можете легко додати нові вузли кластера для розширення обчислювальних потужностей.
Кластер Proxmox забезпечує гнучкість, відмовостійкість і простоту управління у віртуалізованому середовищі, що робить його популярним вибором для побудови інфраструктури віртуалізації.
Найкраще використовувати кластер Proxmox з трьох вузлів, як рекомендують розробники, але це дорого. Тому розробники придумали так званий QDevice, який я не буду розглядати в цій статті.
QDevice в контексті системи управління віртуалізацією Proxmox VE (Proxmox Virtual Environment) – це віртуальний пристрій, який використовується для моніторингу та аналізу якості обслуговування в середовищі віртуалізації. QDevice в Proxmox VE дозволяє контролювати продуктивність віртуальних машин, вимірювати параметри мережі та реагувати на можливі проблеми в роботі віртуальної інфраструктури. Це допомагає мережевим адміністраторам ефективно керувати ресурсами та забезпечувати високу доступність та продуктивність віртуалізованих середовищ.
Якщо у вас також є сервер, на якому ви можете запускати Debian і QDevice, то це буде краще, ніж двовузловий кластер, так як в цьому випадку спрацює механізм високої доступності і багато питань відпадуть самі собою.
Двовузловий кластер може бути використаний для покращення ручної відмовостійкості та забезпечення деякого резервування, але він не забезпечує так званого кворуму, який необхідний для автоматичного прийняття рішень у разі відмови вузла. У двовузловому кластері можна використовувати методи реплікації даних або налаштування пасивного резервування, щоб забезпечити частковий захист від відмови. Простіше кажучи, висока доступність ХА не працює, а перемикання віртуальних машин з вузла на вузол можливе лише в ручному режимі.
Створення кластера
Для створення кластера необхідно дотримати кілька умов:
- Назва пулів ZFS має бути однаковою. Наприклад, rpool для системного диска або dpool для другого пулу на окремих дисках.
- Віртуальні машини не повинні створюватися на вузлі з’єднання, тоді їх можна створити.
- Операція виконується від користувача root
Починати потрібно з ще основного вузла, на якому створюються віртуальні машини. Далі вузли в кластері стануть рівноцінними.
Зайдіть в дата-центр, кластер і натисніть створити кластер.
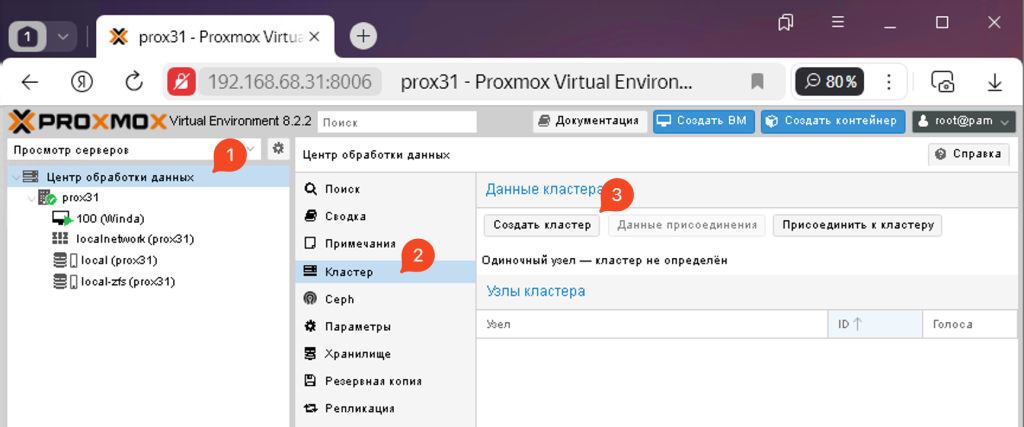
У вікні придумайте назву для кластера і виберіть ланки, за якими кластери будуть спілкуватися один з одним. У моєму випадку таке посилання лише одне.
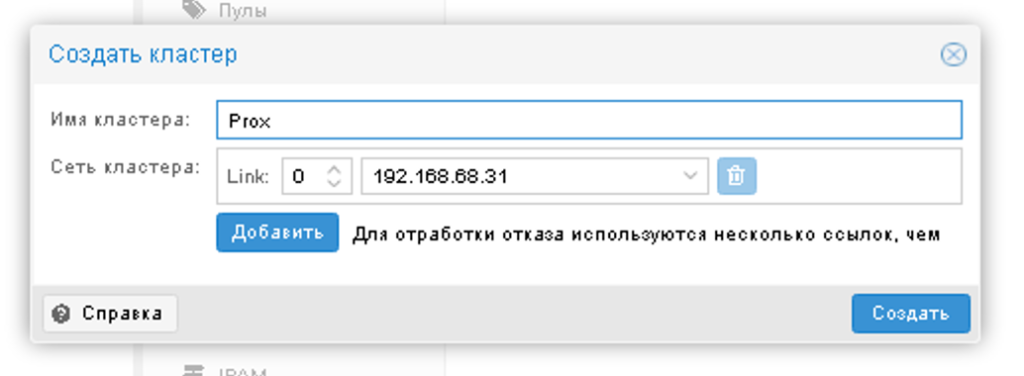
Кластер створюється на першому вузлі.
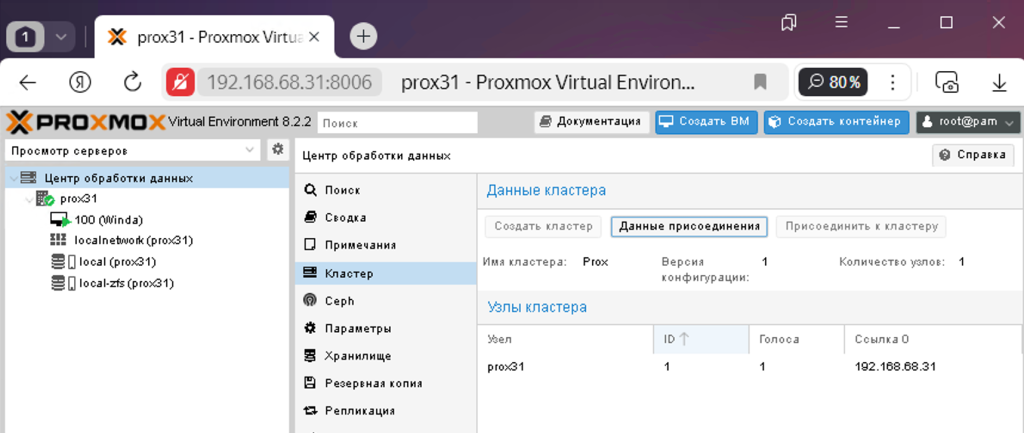
Далі потрібно натиснути на кнопку приєднання і скопіювати дані за допомогою спеціальної кнопки
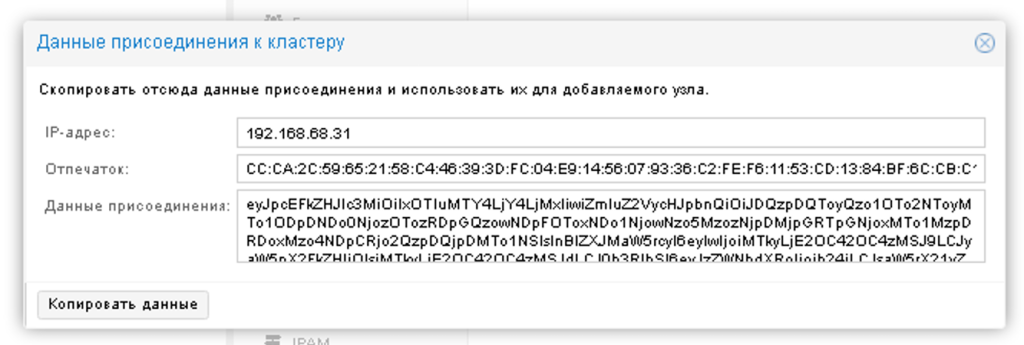
Далі переходимо до другого вузла, дата-центру, кластера та натискаємо приєднатися до кластера
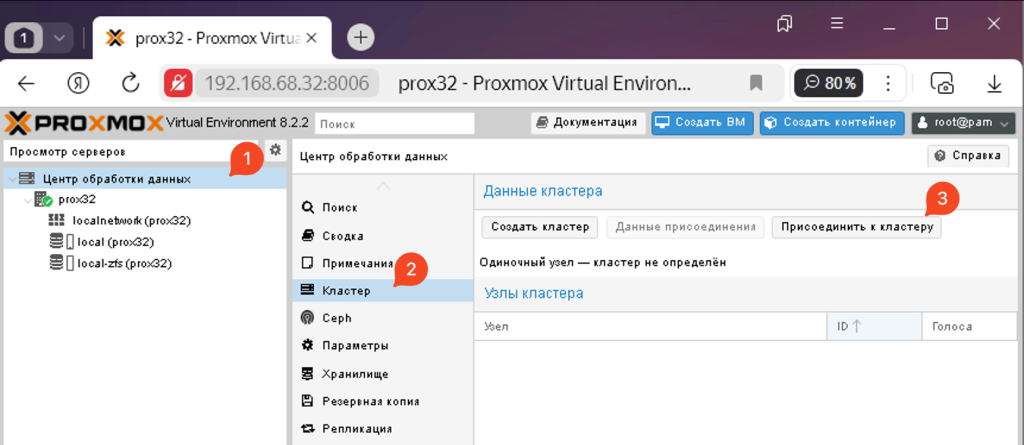
Потім у вікні вставте дані для приєднання до кластера і він сам відобразить потрібну IP-адресу. Вам потрібно буде лише ввести пароль від користувача root першого вузла, вказати IP-адресу вашого вузла та приєднатися до кластера
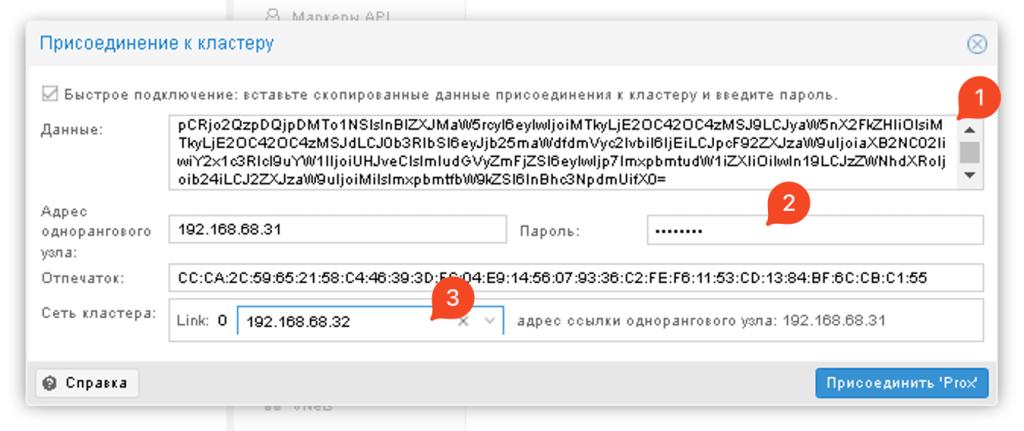
Після цього один вузол почне приєднуватися до кластера. Потрібно почекати і оновити сторінку через пару хвилин, так як вона перестане оновлюватися
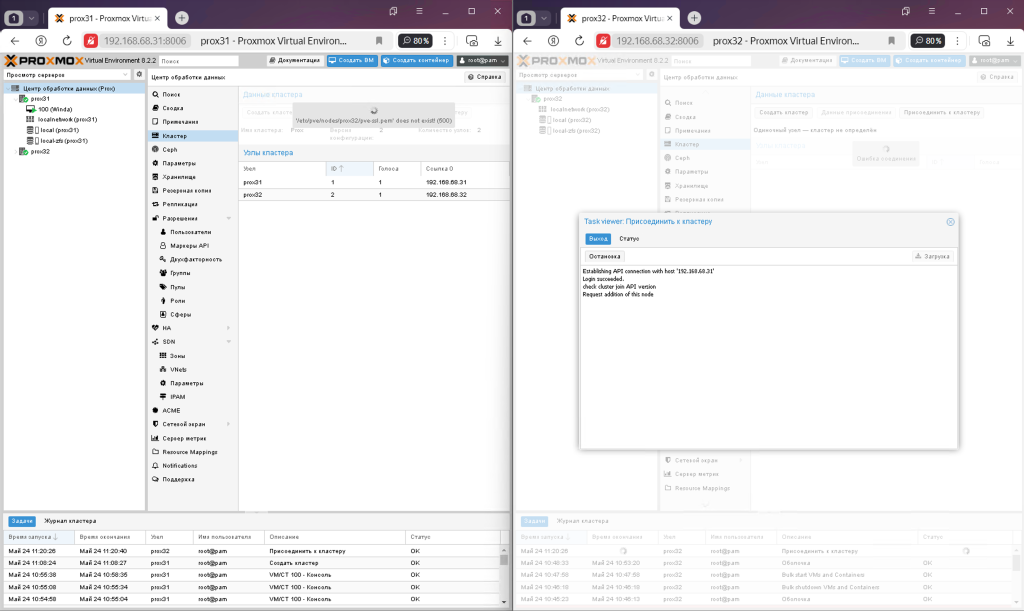
Після оновлення сторінки ви можете побачити, що обидва вузли знаходяться в одному кластері, і який би вузол ви не перейшли, вони будуть відображатися і управлятися з цього вікна.

По суті, Proxmox – це кластер з двох створених і працюючих вузлів, але що він нам дає?
Міграція віртуальних машин
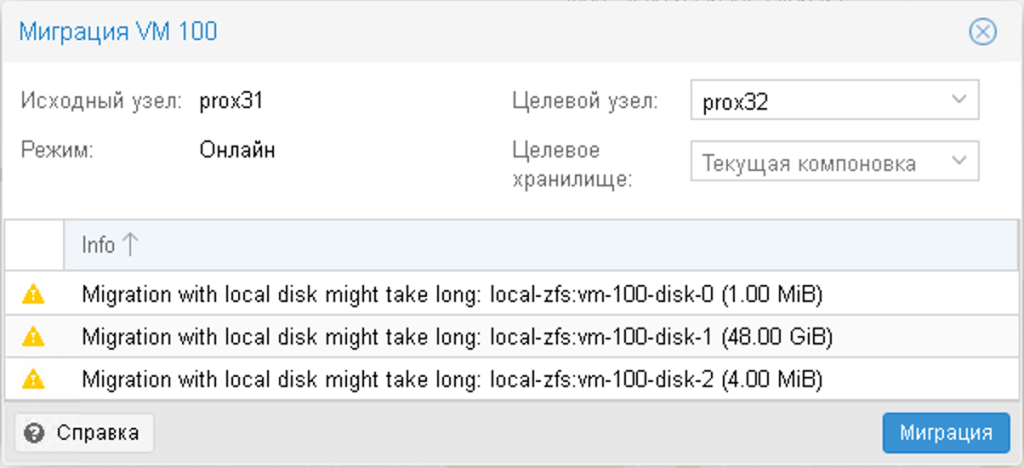
Найперша перевага, яку дає таке скупчення з двох вузлів – це можливість міграції. Клацніть правою кнопкою миші по віртуальній машині та виберіть Перенести.
Також нагадую, що повинні бути створені пули ZFS з однаковим ім’ям або повинні бути шари зберігання ISCSI або NFS.
Гостьові додатки повинні бути встановлені у віртуальній машині
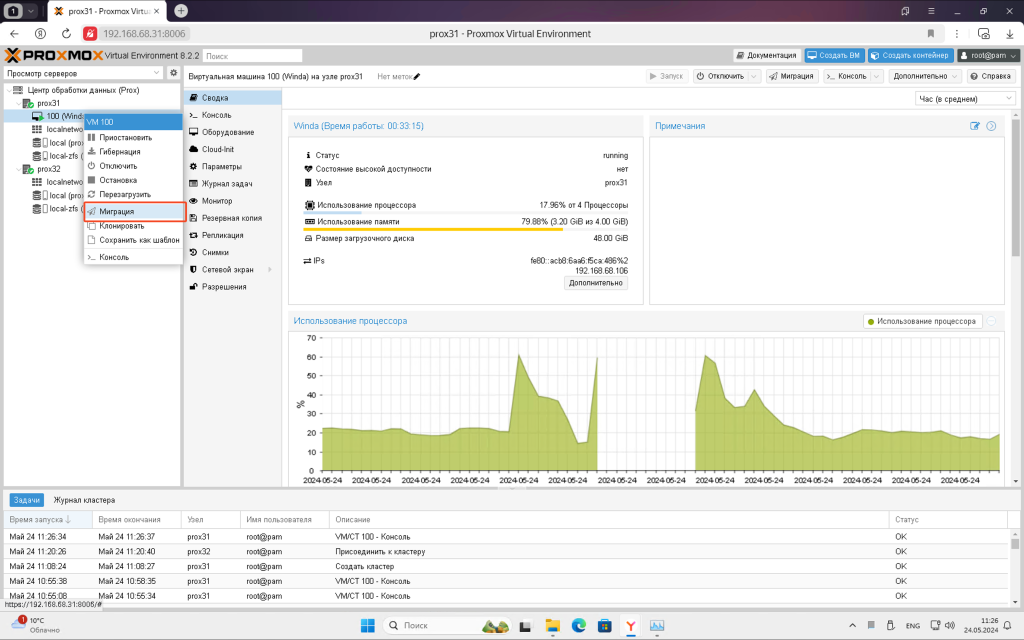
У вікні система попередить вас, на які диски і на який вузол вона буде передаватися.
Якщо спостерігати за статусом міграції, то можна побачити, як всі диски та оперативна пам’ять, якщо на той момент працювала ВМ, переносяться на інший вузол. Потрібно просто чекати. У цей час віртуальна машина буде працювати і навіть не помітить процес міграції.
Обсяг переданих даних залежить від фактичного обсягу переданих даних, а не від обсягу, виділеного віртуальній машині. Наприклад, якщо виділено 8 ГБ оперативної пам’яті, а віртуальна машина використовує лише 3,5 ГБ, то буде перенесено саме 3,5 ГБ, а не всі 8 ГБ.
Якщо диски віртуальної машини знаходяться в загальному сховищі ISCSI або NFS, то міграція буде миттєвою, потрібно буде тільки перенести оперативну пам’ять на інший вузол.
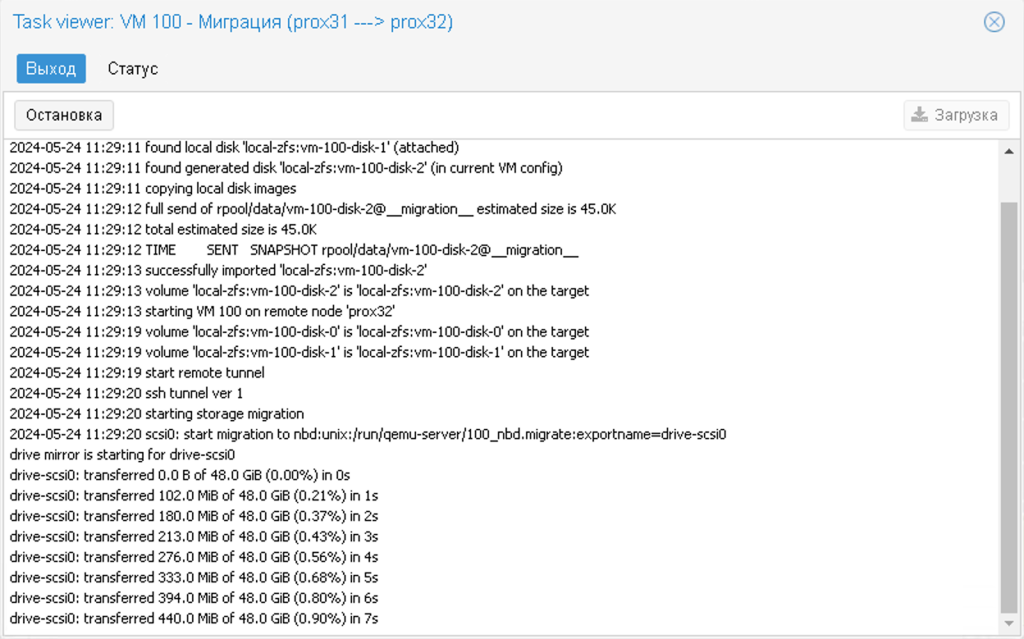
В результаті віртуальна машина перекочує на інший вузол і навіть не буде перезавантажуватися, всі процеси продовжать роботу.

Реплікація ВМ
Другою перевагою кластера Proxmox з двох вузлів є можливість реплікації віртуальних машин на інший вузол. Це схоже на резервне копіювання віртуальної машини, але також дозволяє запустити віртуальну машину на іншому вузлі, якщо цей вузол з якоїсь причини перестає працювати.
Якщо диски віртуальної машини знаходяться на загальному сховищі iSCSI або NFS, реплікація не потрібна і не буде працювати.
Реплікація ВМ – це копіювання дисків віртуальних машин у реальному часі на інший вузол. Для цього зайдіть на потрібну віртуальну машину в розділ реплікації та додайте її. Ви можете вибрати, як часто робити реплікацію, все на ваш розсуд. Варіанти варіюються від 15 хвилин до одного разу на тиждень. Частота реплікації вже не збільшить займаний простір на двох вузлах, але система буде робити це частіше.
Перша реплікація буде тривалою, оскільки всі дані були скопійовані, а друга та наступні реплікації будуть швидкими, оскільки копіюватимуться лише зміни між поточним станом та попередньою реплікацією.
Після створення реплікації вона почне своє перше виконання, але статус деякий час буде в очікуванні.
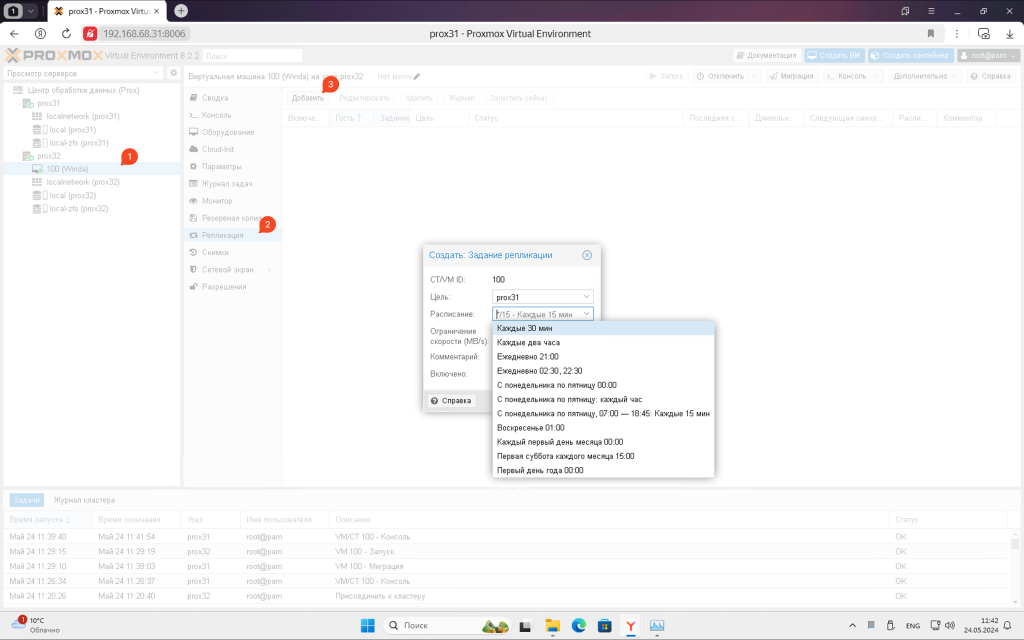
Ви можете переглянути статус реплікації в журналі.
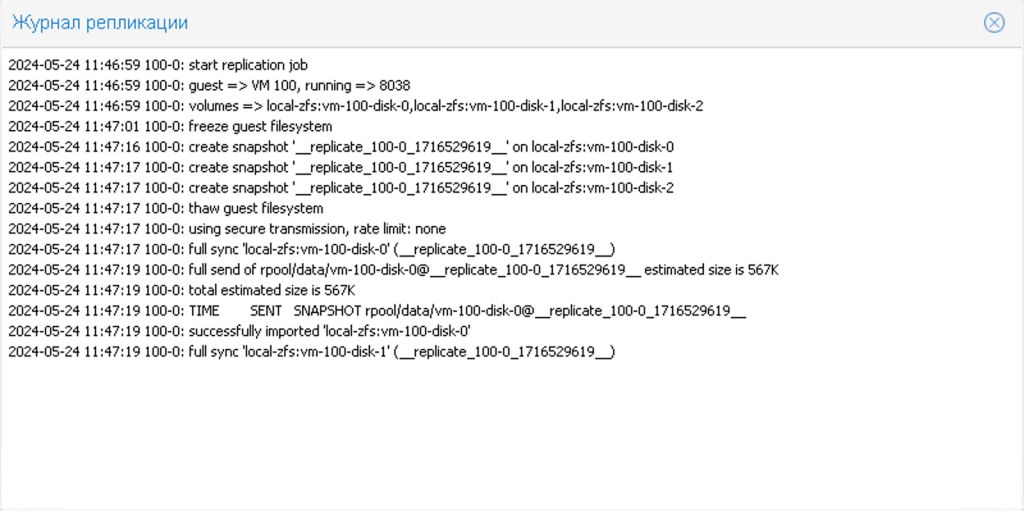
Коли перша реплікація буде завершена, ви можете перенести віртуальну машину під час роботи обох вузлів. Така міграція буде дуже швидкою, так як система буде копіювати не всі дані, а тільки ті зміни, які відбулися з моменту останньої реплікації. Загалом, дуже швидко.
Крім того, налаштування реплікації автоматично перейдуть на нові правила самостійно після міграції. Наприклад, якщо реплікація була виконана з PVE2 в PVE1 перед міграцією, то реплікація буде виконана з PVE1 в PVE2 після міграції.
Несправний один вузол
Ще однією перевагою кластера є можливість відновлення роботи віртуальної машини з пошкодженого вузла на виробничий. У випадку з трьома вузлами це може бути зроблено автоматично, а оскільки у нас всього два вузли, то доведеться робити це вручну.
Припустимо, у нас зламався другий вузол PVE32 з віртуальною машиною, яку потрібно відновити. Тут слід зазначити, що ви повинні були заздалегідь налаштувати реплікацію.
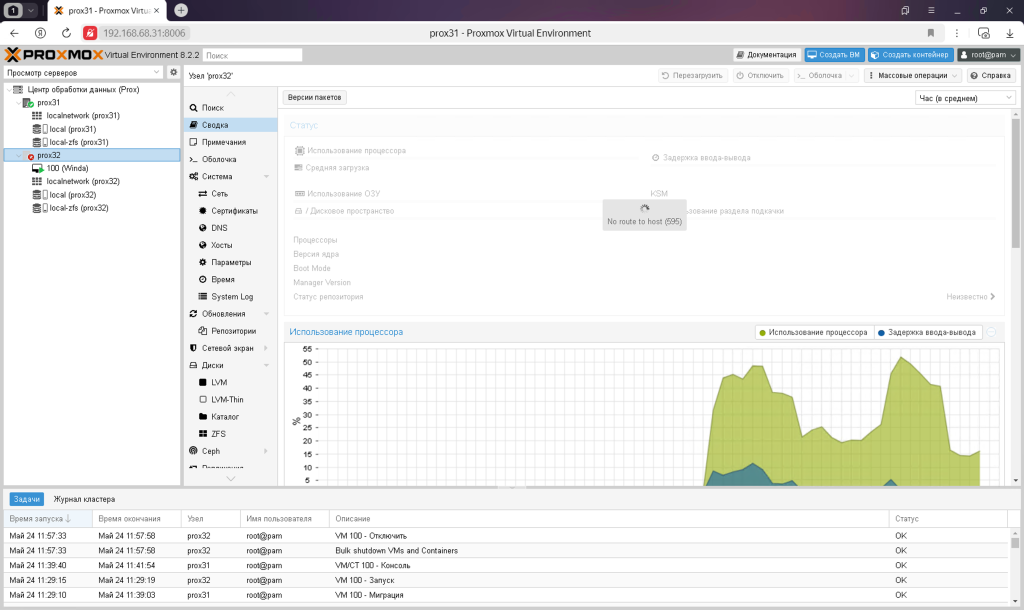
Перше, що потрібно знати, це те, що кворум з одним вузлом не працює. Саме тому нам потрібно три з них. Простіше кажучи, кластер з одним вузлом не дозволить змінити що-небудь просто так, навіть для користувача root.
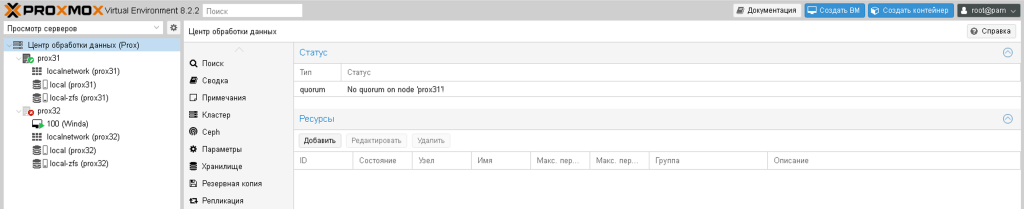
Тому можна тимчасово встановити кворум на 1, щоб він перейшов у робочий стан
pvecm expected 1
І кворум перейде в стан ОК
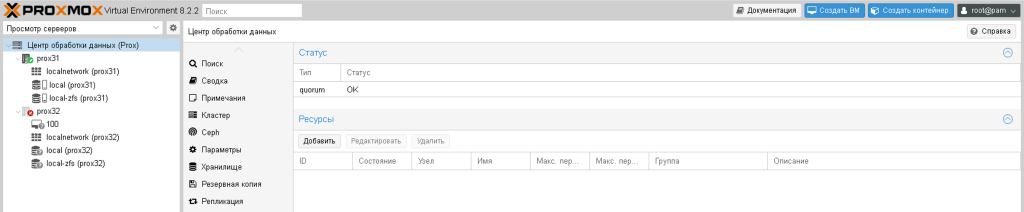
Тепер ви можете перемістити віртуальну машину з несправного PVE32 на справний PVE31.
Нагадуємо, що у вас має бути зроблена хоча б одна реплікація. Дані між реплікацією та поточним станом віртуальної машини, природно, будуть втрачені. Тому реплікацію слід проводити частіше.
Найкращим варіантом є зберігання дисків віртуальних машин на спільному сховищі iSCSI або NFS
mv /etc/pve/nodes/pve32/qemu-server/100.conf /etc/pve/nodes/pve31/qemu-server/
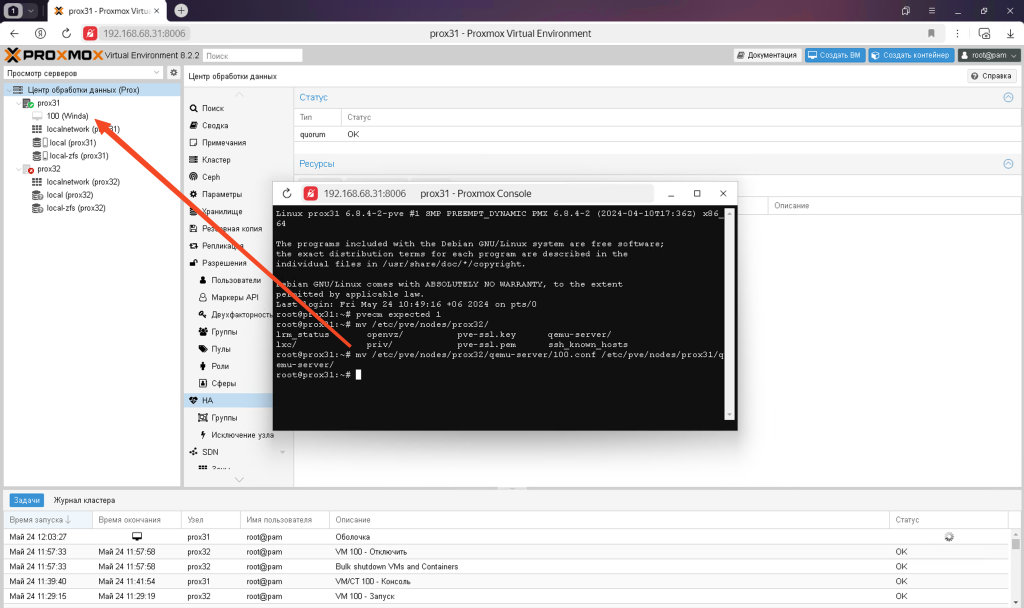
Залишиться тільки запустити віртуальну машину і виправити несправний вузол. Коли несправний вузол запуститься, ви можете знову перенести на нього віртуальну машину або залишити її на поточному вузлі.
Головний вузол
Для будинку на постійній основі мені потрібен лише один вузол кластера Proxmox, другий я час від часу підключаю. Тому для мене важливо, щоб навіть з одним вузлом все працювало як годиться.
Для того, щоб вузли в кластері функціонували без помилок, їм потрібен кворум, який досягається мінімум двома голосами. За замовчуванням кожен вузол має один голос.
Це означає, що якщо будь-який вузол виходить з ладу, другий вузол автоматично стає несправним, оскільки кворум не можна досягти одним голосом. Коли це відбувається, ви не можете створювати, видаляти віртуальні машини. Можливо, щось інше неможливо. Загалом, будуть помилки при відмові.
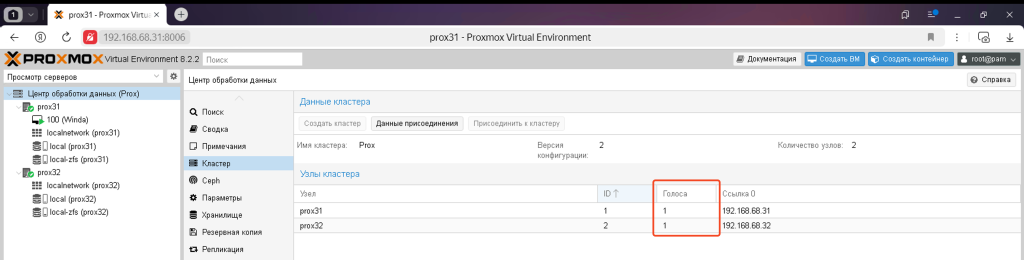
Щоб вирішити цю проблему, можна виділити один вузол в якості основного вузла і дати йому 2 голоси замість одного. Для цього потрібно відредагувати один файл:
nano /etc/pve/corosync.conf
У цьому файлі потрібно змінити два параметри:
- Кворум голосів – це кількість голосів, які має вузол. Змініть значення потрібного вузла з 1 на 2
- config version – змініть це значення ще на один пункт. Це потрібно для того, щоб ці зміни синхронізувалися між усіма двома вузлами або, якщо у вас їх більше, то між усіма
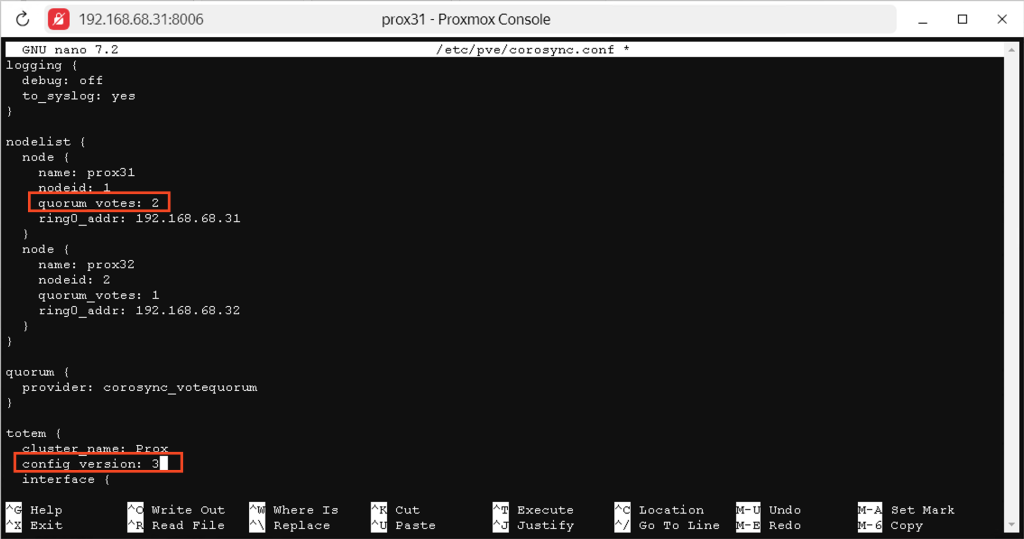
І відразу після цього ви побачите результат своєї роботи
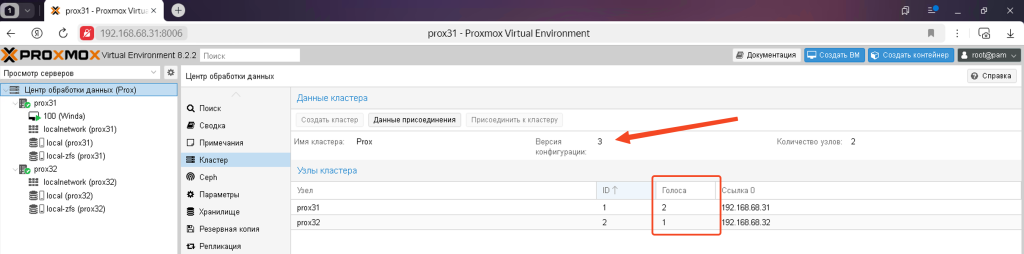
Тепер другий вузол PVE32 може бути відключений при необхідності, і його відключення ніяк не вплине на роботу іншого вузла PVE31.
Тепер ви знаєте, як зробити кластер Proxmox з двох вузлів, як це все працює, для чого він потрібен і в чому є особливості.